
Table of Contents
- Machine Learning & Deep Learning Applications
- Distributed Databases
- S0 Galaxies
- Virtual Observatory
- Variability Estimation and Counterpart Search
Machine Learning & Deep Learning Applications
Astronomy has always been a data driven science. And the volumes of data continue to explode with each new upgrade to the instrument and / or the data collection pipelines. Many studies require manual inspection by human experts who sit down, stare at various properties, images and plots in order to classify these objects. With growing volumes, it is simply not possible to do this anymore. Thus there is a need to develop Machine Learning algorithms that can do this efficiently on behalf of the human experts. Below are some interesting applications I have been working on with a team of researchers from around the world.
- Classification of stellar spectra.
- Interpolation of spectra across the temperature, surface gravity and metallicity parameter space.
- Detection of bars and other morphological features in galaxy images.
- Leveraging NLP techniques to mine information recorded by observerd and engineers using natural language logs.
Distributed Databases
Scientific databases, like those in Astronomy, are increasing in volumes at tremendous rates. The usual paradigm of arranging the data in the form of related tables and store them in a relational database system is proving to be insufficient given current volumes. Volume however is not the only problem - there is a need to efficiently process these data in a manner chosen by the user of the data i.e. not preprocessing but live processing. For this purpose, it is now essential to move to distributed databases. Distributed databases however come with their own challenges. My work in this area includes:
- Design and development of components for "QuickDB", a distributed database designed for the Subaru Public Data Release.
- Study of off-the-shelf NoSQL databases with emphasis on scientific use cases.
- An in-depth study of MongoDB in particular.
S0 Galaxies
Galaxies come in a variety of shapes, what we like to call ‘morphologies’. What shapes these galaxies? How are the different shapes related to each other? Do galaxies tend to start out in one shape and move towards another? These are the outstanding questions in galaxies which have not been answered fully despite decades of research. When we see galaxies in the nearby Universe, trying to arrange them in a sensible manner is a first step towards understanding them. The famous astronomer, Edwin Hubble, was the first to try and come up with such an arrangement and his effort is captured in the diagram below known as the tuning fork diagram.
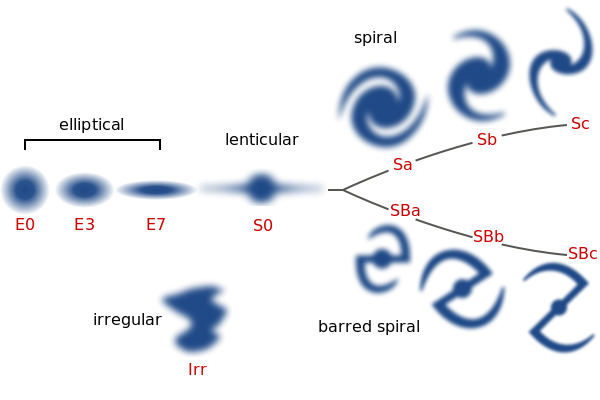
The elliptical galaxies lie towards the left and generally comprise of a single component of stars i.e. all the stars appear to be a part of the same ellipsoidal shaped collection. The galaxies towards the right are called spirals and contain multiple components of stars. One group of stars form what appears to be a spherical structure, known as the bulge while another group forms a flattened structure, known as the disk. In this disk, one can find beautiful spiral patterns. Now, imagine a similar structure containing a bulge and a disk but without the spiral patterns i.e. a ‘plain disk’ - such a galaxy is called an S0 galaxy or a lenticular galaxy.
The S0 galaxies lie at the junction of the tuning fork because it was envisioned as some kind of a transition object between ellipticals and spirals. But does this diagram paint the correct picture for S0 galaxies from the point of view of their formation and their inter-relationships with other galaxies? Research seems to suggest - no! So, what exactly are S0s? Are they all alike? How do they form? These are the kind of questions I have tried to answer in my PhD research. For more details, visit my publications page.
Virtual Observatory
Modern astronomy is a very data intensive science. This means a lot of the progress in Astronomy can be made only by increasing the mastery over the data. But mastery over data is not an easy task. Imagine a world of yester-years where every single observatory around the world used its own formats, its own methods of analysis, its own methods of storing and labelling the data and its own way of presenting the data to the world (after having published as much science from it as possible, of course!). Such a world would be highly chaotic! Every time an astronomer wants a different type of data on a given object, he/she would have to spend immense time just understanding the interfaces, the formats etc.
Enter Virtual Observatory as a solution. It is not a simulated telescope, like some are led to believe when they hear the term. Instead, it is a collection of standards and protocols. And no, it is not an imposition on people to abandon their custom solutions for data storage and service. It is instead a collection of simple nomenclatures, descriptions, methods of serving data etc. that data providers can adopt that makes their data searchable from a central registry. So, Virtual Observatory acts as a very powerful, efficient interface between the users and the data repositories, allowing users to use simple tools which can search and acquire the data users are looking for. The existence of standards also means that the developers of tools for analysis of astronomical data can work independently with minimal coordination, so long as they keep themselves well versed with the standards of how data can be described and exchanged.
For more details, you can visit the official IVOA web page. There is a dedicated site for Indian Chapter of VO. My contributions to the Virtual Observatory project include * testing and development of AstroStat * education and outreach * beta-testing of tools such as IRIS.
Variability Estimation and Counterpart Search
Several astrophysical objects in the sky actually change their properties as a function of time. The simplest property whose behavior in time can be studied is the brightness of the object. This is what we call the variability of the object. So, how do you know if a source is varying with time? Simple, you measure its brightness at a time ‘t1’ and then again at a time ‘t2’. If the two brightness measurements are different, we know that the object is varying … well - no! One needs to understand that the source brightness will appear to vary even if it is actually not. This is because of both the noise in our measurements and noise in the source as well. So, our rather simple task of determing whether an object varies, becomes a complex one. We need to be able to differentiate between actual variability of the source and what appears to be variability because of noise. I’m involved in a group studying methods by which this can be done.
Eventually, one would like to employ such methods in counterpart searches. X-ray telescopes typically have large positional uncertainties. This means that it is possible for several objects to be in what is the most likely region from which an X-ray emission was observed. The actual object which emits the X-rays is known as the counterpart and determining the most likely counterpart for a given X-ray source is an interesting problem in Astronomy.